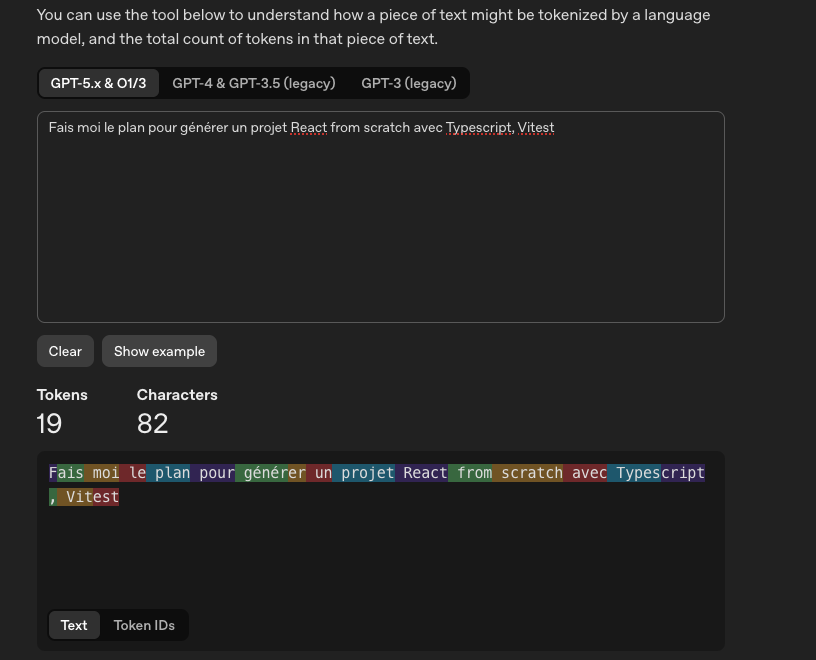
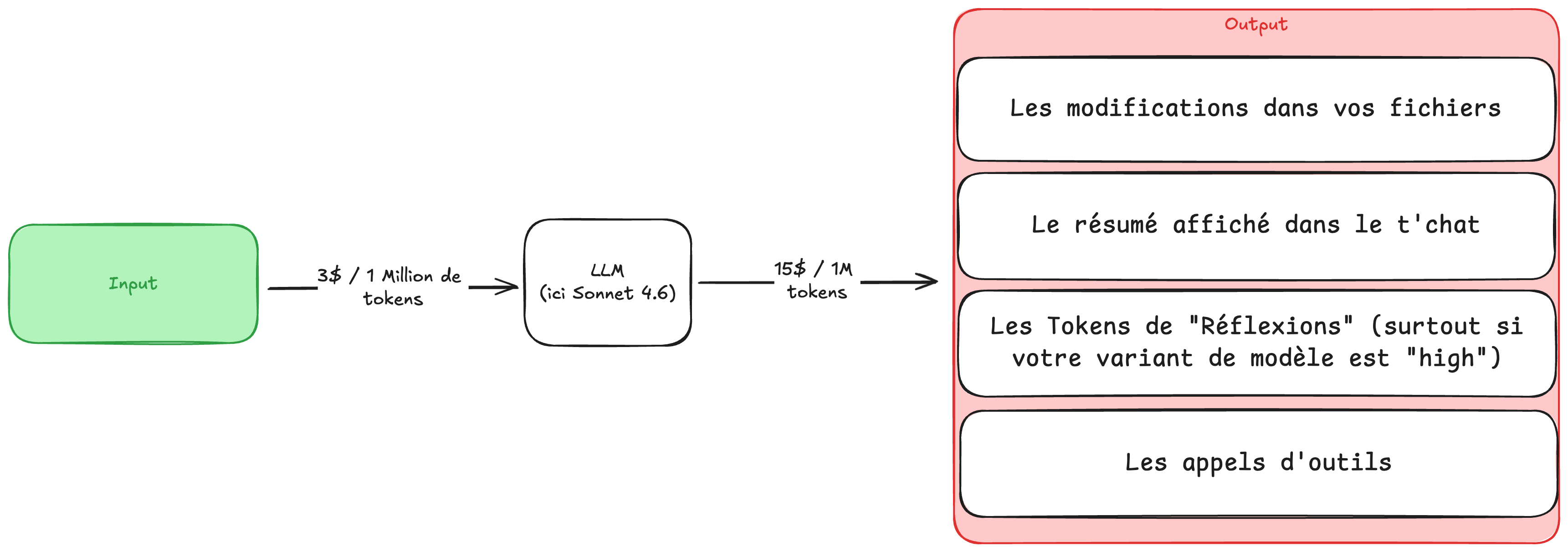
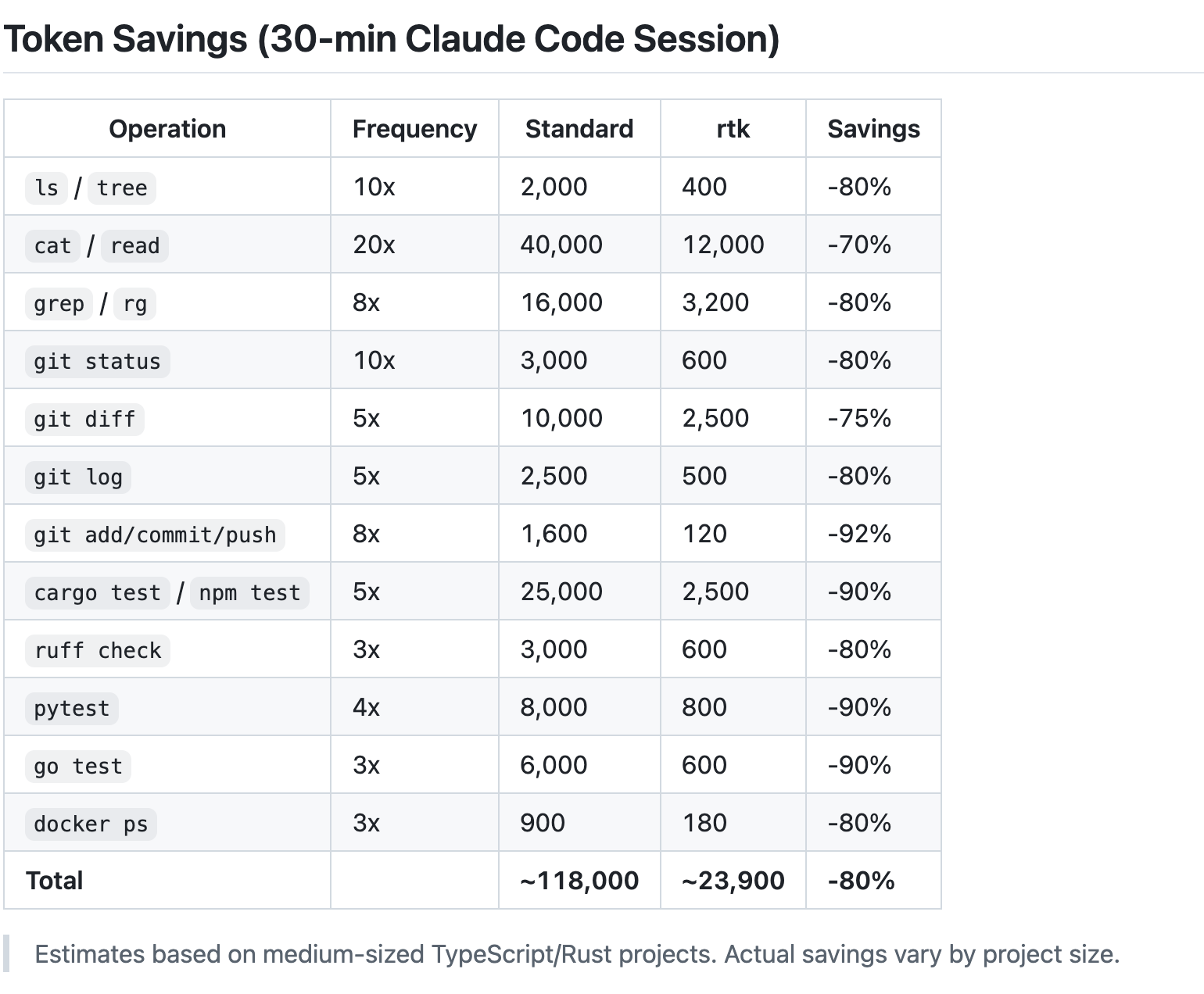
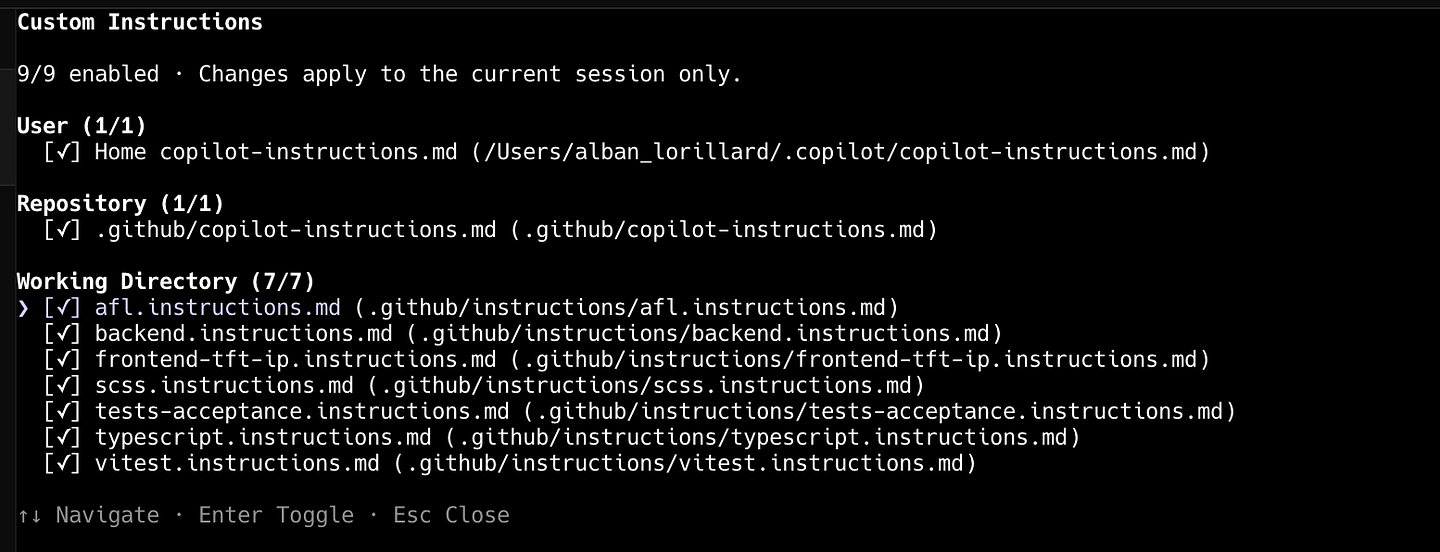
Recommandation 06
Plus vous activez d'outils, plus le contexte grossit : instructions de skills, schémas MCP, descriptions, paramètres et exemples sont renvoyés à chaque requête.
Skills
- Instructions ajoutées au prompt système
- Chaque skill augmente le contexte fixe
- À désactiver quand elles ne servent plus (/skills, puis /new)
MCPs
- Certains n'exposent qu'une fonction "discovery" au départ → économise les tokens
- Une fois découvertes, les autres fonctions s'ajoutent à l'historique
- Plus optimisé qu'un fetch de page HTML brute
Bon réflexe : activer seulement ce qui sert à la tâche en cours.
Sur Copilot CLI : /mcp disable <service> pour couper un MCP, puis nouvelle session si vous avez modifié les skills.