Alors que GitHub Copilot annonce un passage à une facturation à l’usage d’ici juin (au token consommé) et que les modèles, bien que plus performants, deviennent de plus en plus coûteux, adopter un usage économique et intelligent de l’IA devient indispensable. L’heure de l’expérimentation sans limite est révolue. Cet article vulgarise le fonctionnement des LLM sur le sujet de la consommation de tokens et propose une liste de bonnes pratiques pour réduire vos coûts. Ces méthodes favorisent également l’efficacité (moins d’hallucinations et d’allers-retours), tout en limitant l’empreinte énergétique dans les data centers.
Je ne traiterai pas ici des spécificités contractuelles de Copilot, mais de l’usage des tokens d’un point de vue généraliste.
Tokens d’entrée, de sortie, de cache : comprendre la mécanique
Qu’est-ce qu’un token ?
Le token est la plus petite unité linguistique utilisée par l’IA pour décomposer le langage, l’analyser et générer une réponse. Le site Tokenizer d’OpenAI permet de visualiser comment un prompt est segmenté selon les modèles GPT.
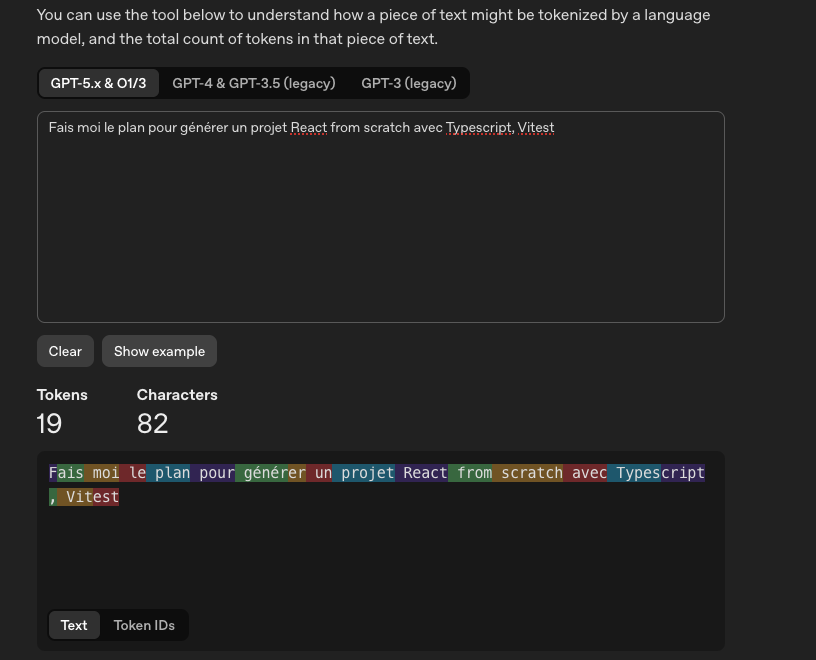
Attention : un même prompt n’équivaut pas au même nombre de tokens selon le modèle utilisé. En complément, le site Claude Tokenizer est également intéressant car il compare les modèles Claude avec ses concurrents.
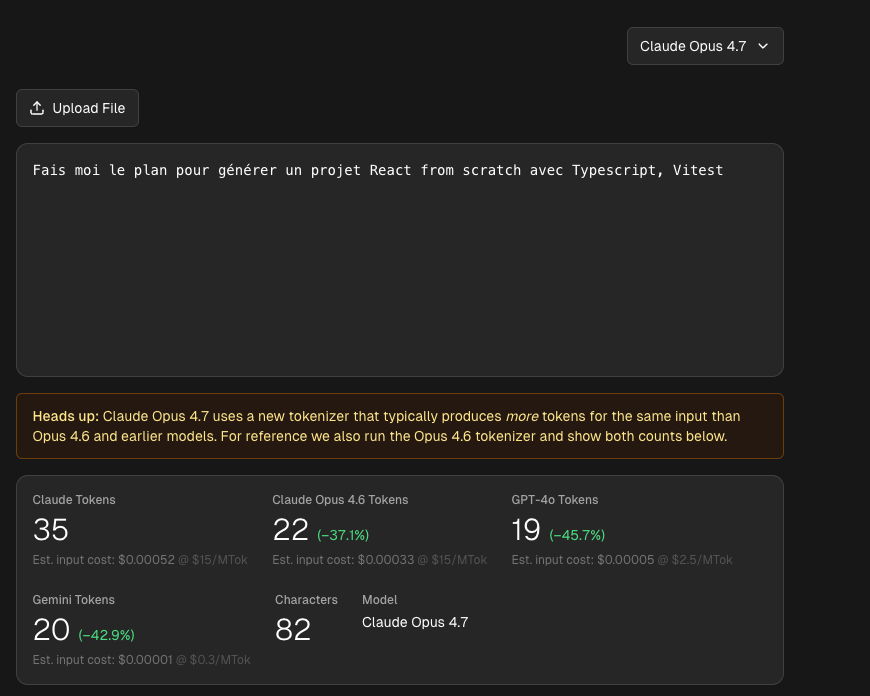
Plus concrètement, sur la page de comparaison des modèles d’Anthropic on s’aperçoit que pour 1 Million de Tokens, on peut caser environ 1 Millions de caractères de plus dans le context de Sonnet 4.6 versus celui d’Opus 4.7.
À retenir : pour un même prompt, plus un modèle est performant, plus il consomme de tokens.
Les tokens d’entrée (Input Tokens)
On pourrait croire que seuls les mots tapés comptent. C’est faux. Vos tokens d’entrée regroupent l’intégralité du contexte envoyé au modèle :
- Votre prompt (la requête actuelle)
- Les instructions personnalisées (AGENTS.md, .instructions.md)
- L’historique de la conversation
- Le contexte implicite de l’IDE (fichiers ouverts, état Git, sélection)
- La sortie des outils (résultats du terminal, logs)
C’est assez intéressant d’ouvrir Copilot CLI sur une nouvelle session et de faire un /context :
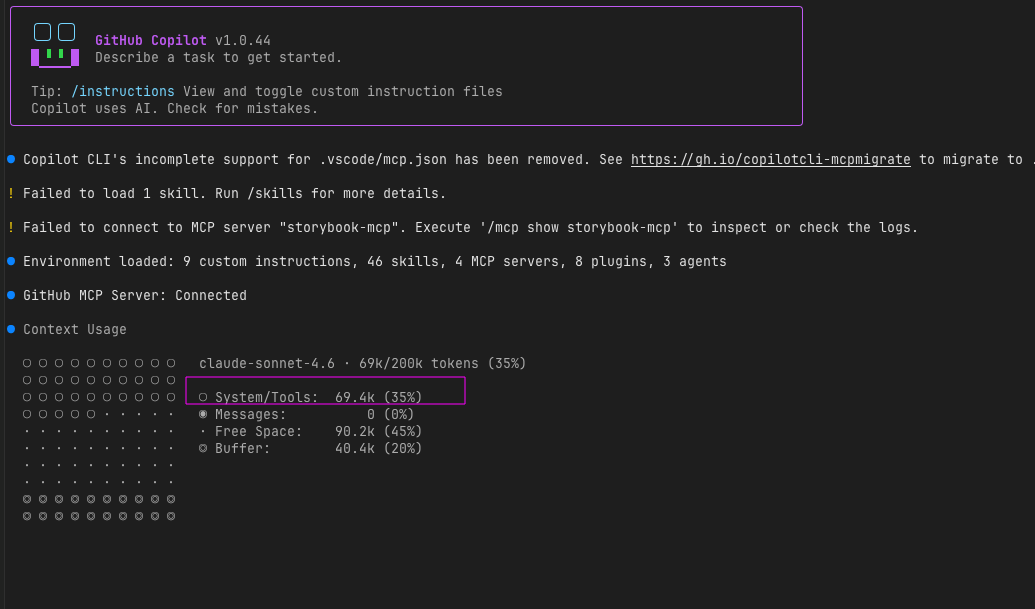
Selon votre configuration, le « ticket de départ » — c’est-à-dire le contexte déjà chargé avant le premier prompt — est plus ou moins volumineux. Ici, on part avec 70 000 tokens de contexte avant même d’avoir posé une question. C’est un signal d’alerte qui invite à revoir et optimiser sa configuration.
Si vous dépassez la limite de la fenêtre de contexte, il faudra compresser — et ça coûte. On y reviendra.
Pour donner un ordre de grandeur, de manière très approximative, 1 million de tokens représente environ 750 000 mots, soit l’équivalent d’une encyclopédie de 2 000 à 3 000 pages.
Les tokens de sortie (Output Tokens)
Les tokens de sortie sont plus concrets : une fois le contexte envoyé au LLM, celui-ci produit du contenu, qui est lui aussi facturé (5x plus cher).
Vous avez donc :
- Les tokens de sortie pour le code modifié dans vos fichiers
- Les tokens de sortie pour la réponse produite en sortie de la console
Mais il y a une surprise : les tokens de réflexion sont également comptabilisés comme tokens de sortie. Ce sont les sorties visibles dans la console où l’on voit le modèle travailler, se poser des questions, raisonner… Nous verrons plus loin que les variantes « High » peuvent coûter cher pour cette raison.

Pour donner un ordre de grandeur (il s’agit ici des tarifs en facturation directe via l’API Anthropic, pas des prix Copilot) : Claude Sonnet 4.6 se facture 3 $ / million de tokens en entrée et 15 $ / million en sortie ; Claude Opus 4.7 monte à 5 $ / million en entrée et 25 $ / million en sortie. Les tokens de sortie coûtent donc environ 5 fois plus cher que les tokens d’entrée. Ce ratio est un repère utile pour comprendre où se concentrent les coûts, même si les montants réels varient selon votre contrat Copilot.
Les tokens et le cache
Les LLM n’ont aucune mémoire. À chaque interaction, l’intégralité du contexte est donc renvoyée au modèle :
- Vous posez votre question → envoi de tout le contexte avec votre prompt
- Votre agent lance une commande
ls→ renvoi de tout le contexte + le résultat de la commande - Votre agent lit un nouveau fichier → renvoi de tout le contexte + le contenu du fichier
- Et ainsi de suite…

C’est précisément pour ça que les fournisseurs ont mis en place du prompt caching : tant que le début de votre prompt reste strictement identique d’une requête à l’autre, cette portion peut être servie depuis un cache, à un tarif très réduit.
Côté OpenAI, le cache fonctionne automatiquement, sans aucun paramètre à activer, et sans surcoût. Réduction jusqu’à 90 % du coût des tokens d’entrée sur un cache hit.
Chez Anthropic, le mécanisme est très différent. Le cache doit être explicitement demandé par l’application qui appelle l’API. Anthropic facture l’écriture dans le cache (x1.25 par rapport à l’input token pour 5 min de cache), mais la partie en cache sera facturée 90% moins cher lors des hits.
Le problème c’est que les outils Copilot CLI / OpenCode sont assez obscure sur la partie “Cache”. Les modèles d’OpenAI ont donc l’air d’en bénéficier par défaut, ce qui ne semble pas le cas des modèles d’Anthropic. Vous pouvez regarder le paramètre setCacheKey pour Opencode / Anthropic
Les bonnes pratiques à mettre en place dès maintenant
1 — Optimiser l’output des commandes CLI
C’est sûrement l’action la plus rapide et la plus efficace. RTK et Snip reposent sur un principe très simple : s’intercaler entre vos commandes CLI habituelles et votre agent.
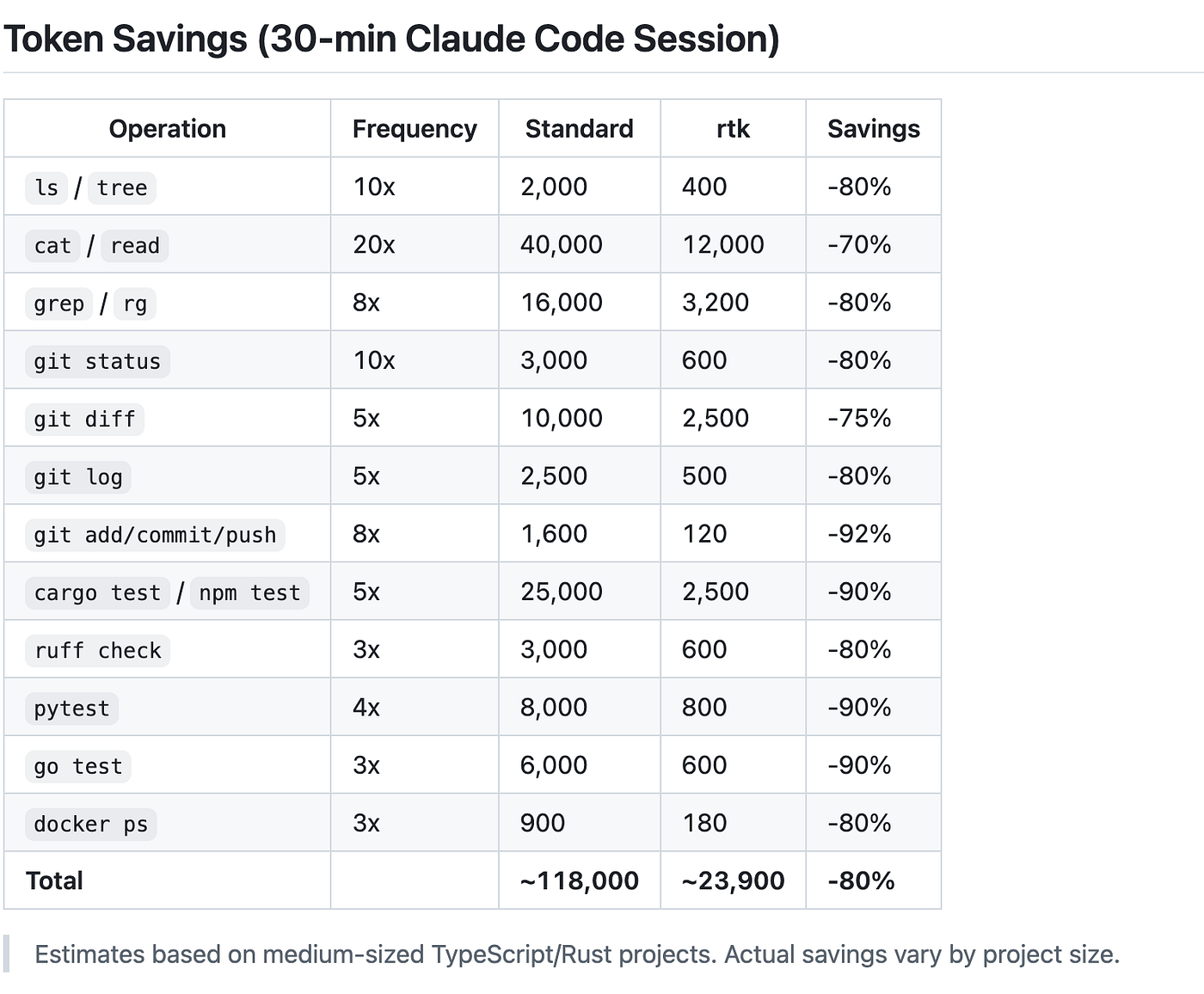
L’outil est livré avec une instruction à ajouter à votre agent pour lui signifier : « N’utilise plus les commandes par défaut, utilise celles de RTK. » Ainsi, l’agent ne fera plus de ls pour lister les fichiers d’un dossier, mais un rtk ls, dont la sortie est optimisée en tokens.
Si vous utilisez des outils pas encore pris en charge par ces CLI-proxy, rien ne vous empêche d’ajouter dans votre package.json (ou autre gestionnaire de paquets) des scripts optimisés pour l’IA — c’est-à-dire en utilisant des arguments qui ont des sorties moins verbeuses quand disponible — et d’ajouter une instruction pour en favoriser l’usage.
2 — Optimiser vos Outputs avec une instruction globale
Il ne faut pas en abuser, et la garder simple, mais il est important d’en avoir une concise, car elle influencera l’ensemble de vos sessions futures. On parle ici d’une instruction générale (selon l’outil : ~/.config/opencode/AGENTS.md pour OpenCode, ~/.copilot/copilot-instructions.md pour Copilot…). Ce contexte est chargé à chaque prompt — ce sont donc des tokens d’entrée consommés d’office. On peut le voir comme un malus d’entrée, mais qui permet de gagner sur les tokens de sortie (ceux qui coûtent le plus) : en évitant, par exemple, que les agents prennent trop de libertés en effectuant des tâches non demandées et coûteuses, en répondant de façon directe, ou en tournant en rond de façon autonome.
Voici un exemple :
Style & Langue
- Français. Direct, concis, sans fioriture ni emoji.
Planification & Scope
- Tâche complexe (>2 fichiers, archi, module) : plan via /plan + validation avant action.
- Respect du scope : signale les problèmes connexes sans corriger.
Git & Sécurité (Validation explicite)
- Git : Pas d’auto-commit ni push.
- Interdit : Déploiement (Terraform, Lambda, infra), API prod, suppression, irréversible.
Décisions & Blocages
- Ambiguïté technique : ne choisis pas, expose les options.
- Échec : Stop après 2 tentatives. Explique : blocage, état actuel, essais réalisés.
Dès que vous le modifiez, gardez en tête le ratio : « Ce que ça va me coûter à chaque requête » vs « Le bénéfice sur un grand nombre de sessions ».
Instructions locales et spécifiques
En complément de l’instruction globale, la plupart des outils permettent de définir des instructions locales, spécifiques à un projet (.github/copilot-instructions.md, .clauderules…). Elles sont chargées uniquement lorsque l’outil est ouvert dans le dossier concerné — ce qui les rend plus ciblées. Mais attention : elles sont toutes injectées dans le prompt système, tout comme l’instruction globale. Le risque est de les laisser s’accumuler et de surcharger inutilement le contexte. Règle d’or : restez extrêmement concis, et ne conservez que ce qui est strictement nécessaire au projet en question.
Désactiver les instructions que vous n’utilisez pas
Copilot CLI vous affiche les instructions chargées via /instructions. Cela varie du dossier en cours. Si vous travaillez sur du backend, vous pouvez désactiver les instructions en rapport avec le front par exemple.
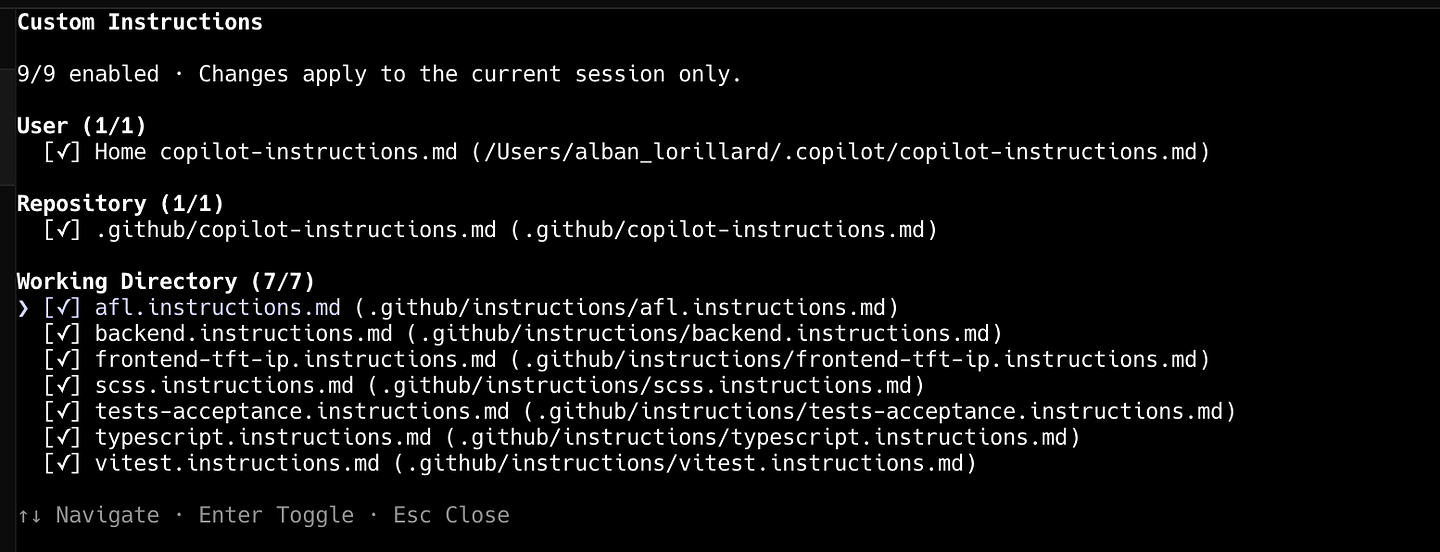
Une fois fait, partez d’une nouvelle session via /new. Dans le prochain /context, le contexte dans “System/tools” devrait avoir diminué.
Malheureusement, Opencode ou le plugin Copilot de VSCode n’ont pas cette fonctionnalité.
3 — Optimiser les outputs avec Caveman
Caveman fonctionne sous forme d’une skill utilisable avec n’importe quel outil IA. Il transforme vos phrases en outputs plus ou moins condensés. Il existe plusieurs modes : « lite », « full », « ultra ». Comme on a vu précédemment que l’historique de conversation était envoyé à chaque fois, cela permet donc d’optimiser votre contexte à chaque échange. Le gain estimé est d’environ 75 % de tokens en moins sur les sorties en mode full ou ultra.
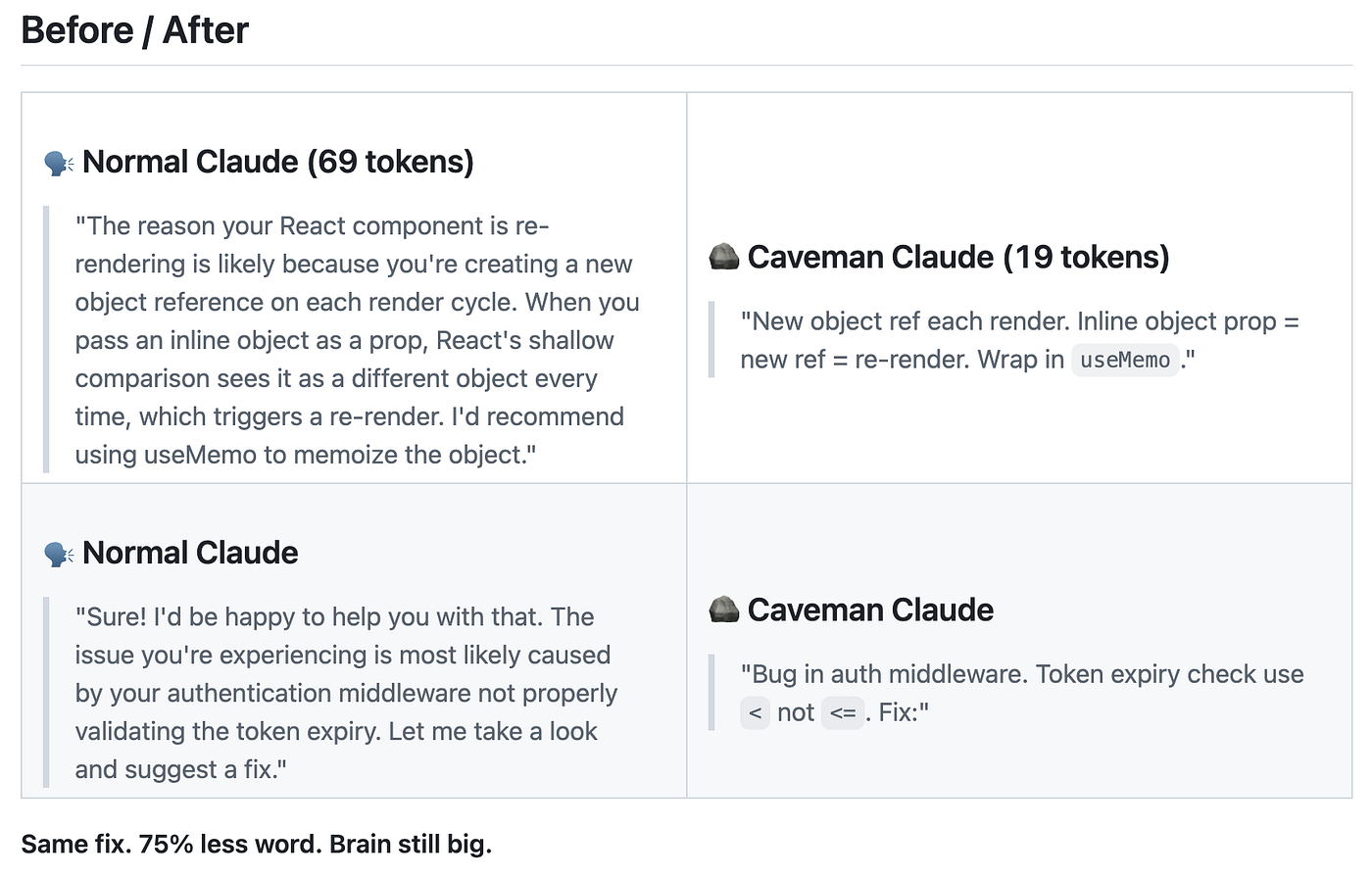
Vous réglez donc la graduation, si vous utilisez le mode ultra, les réponses seront moins “lisible” car très compacté, ce qui peut représenter une charge cognitive supplémentaire pour vous.
4 — Utiliser les bons modèles pour les bonnes tâches
C’est du bon sens, mais n’utilisez pas les modèles les plus puissants (Claude Opus en « High », GPT-5 en « Extra-High »…) pour tout et n’importe quoi.
Claude Sonnet, souvent considéré comme le bon équilibre, peut lui aussi être excessif selon le besoin. Ne négligez pas les modèles légers — Gemini Flash, Claude Haiku 4.5, GPT-5.4 mini — pour les tâches simples.
Abusez des modèles légers.
Personnellement, mon terminal a toujours un onglet OpenCode ouvert sur Gemini 3 Flash (en mode Low ou Medium), nommé « Q&A » (questions & réponses), pour des questions simples, d’ordre général, ou pour des tâches sans complexité. Si votre prompt est précis, concis, délimité, sans fioriture et sans contexte externe (c’est-à-dire que vous ne demandez pas à l’agent d’aller chercher du contexte en dehors de votre prompt), vous disposez d’une solution quasi gratuite. Comme ce sont des modèles moins performants, n’hésitez pas à démarrer une nouvelle session (/new) pour chaque nouvelle question ou tâche.
Méthodologie Architecte/Développeur**
À l’opposé, et contre-intuitivement, il vaut parfois mieux utiliser Claude Opus 4.6 pour préparer un plan précis lorsque la tâche est complexe et nécessite une bonne analyse du code (plusieurs fichiers à lire), plutôt que de partir directement avec Claude Sonnet et devoir le corriger à tout bout de champ. Une fois le plan établi, vous pouvez redescendre sur un modèle moins coûteux. C’est la stratégie de l’architecte (Opus 4.6) et du développeur exécutant (Sonnet 4.6 / GPT-5.4).
L’objectif est d’éviter d’utiliser un modèle sous-performant dés le début, ce qui risquerait de vous entraîner dans un biais de rétroaction : devoir corriger après conception le code produit par l’IA. « Au fait, tu as fait ça, mais je préfère que ce soit comme ça. » Chaque requête corrective augmente le contexte en entrée, génère de nouveaux tokens de sortie, entraîne parfois des compressions (qui coûtent aussi), et vous voilà dans une boucle feedback / implémentation qui peut s’avérer coûteuse in fine.
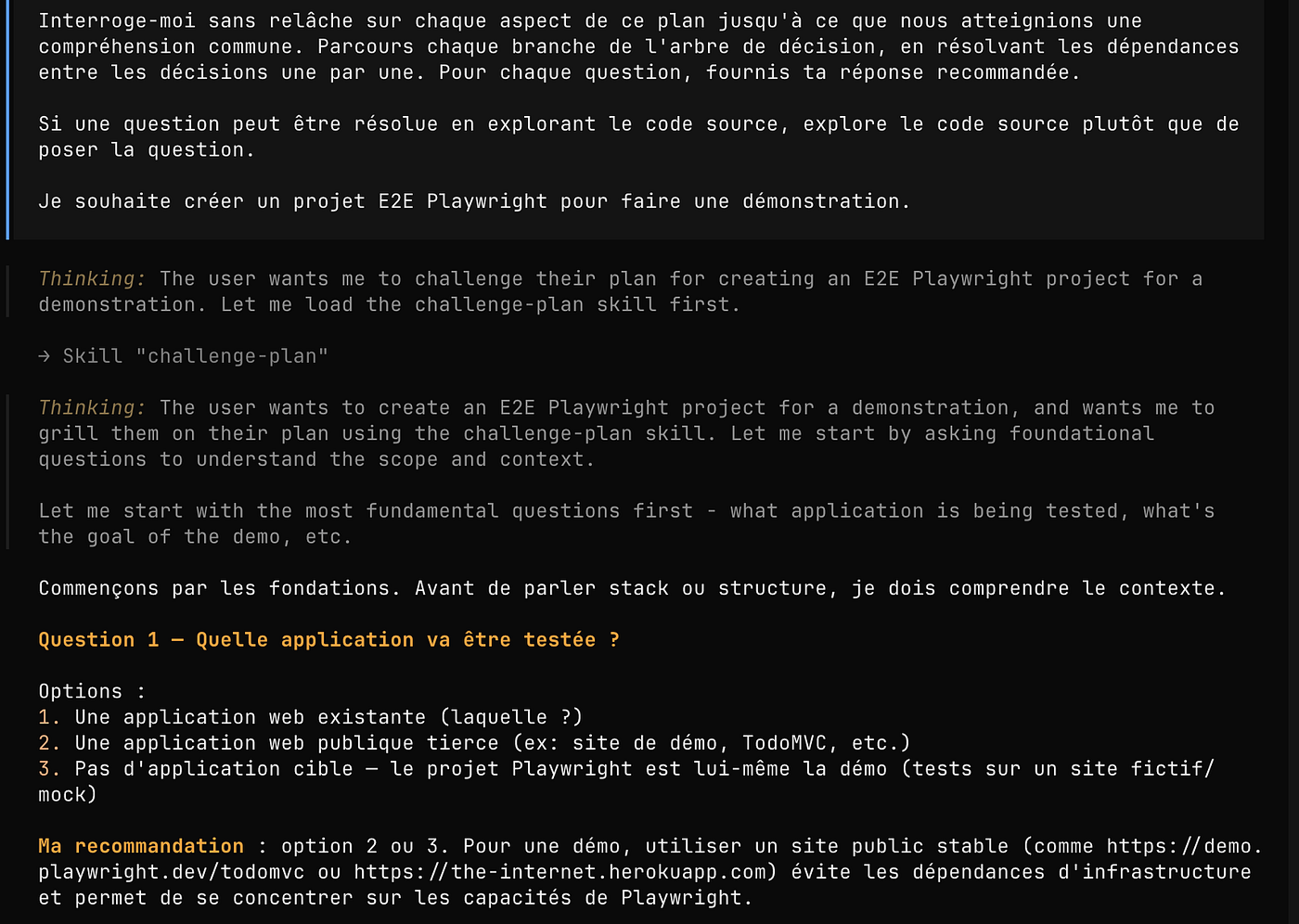
Socratic Prompting**
Ne sous-estimez pas le temps à investir dans la conception d’un plan pour éviter de tomber dans ce biais de rétroaction. La méthode du « Socratic Prompting » consiste à demander à l’IA de vous interroger sans relâche jusqu’à atteindre une compréhension robuste et sans ambiguïté. (Il est possible d’utiliser une skill pour ce genre de cas : exemple).
Mode auto (Utilisateurs de Copilot)
Lors de l’écriture de l’article le mode Auto de Copilot ne choisi pas le meilleur modèle (c’est prévu dans la road map du produit), mais permet d’étaler la charge pour éviter le rate limit et diminuer la latence. Il est donc mieux de maitriser le modèle à utiliser.
5 — Utiliser les bons variants au bon moment (high, extra-high, medium, low…)
Vos modèles disposent de plusieurs variants : Low, Medium, High, Extra-High. Ils ne sont pas tous disponibles pour tous les modèles.
Plus un variant est élevé, plus on lui demande de réfléchir, plus la réponse sera lente mais précise, et plus le contexte fourni en entrée sera exploité.
Globalement, que vous soyez en mode « Low » ou « High », le contexte en entrée (votre prompt, vos fichiers…) est identique. Cependant, en mode « High », on consomme davantage de tokens de sortie, car ceux-ci se composent de deux éléments :
- La réponse effective qui s’affiche dans le terminal une fois la tâche accomplie.
- Les tokens de réflexion (moins mis en avant dans les outils), qui permettent de voir en direct ce que le LLM est en train de faire. Plus le niveau est élevé, plus le budget de réflexion alloué est important, et plus les tokens consommés en sortie sont donc nombreux. Il est donc important de calibrer le bon niveau pour la bonne tâche. Pour une tâche simple (correction, renommage, formatage, code trivial), utilisez « Low » : vous aurez moins de tokens de sortie facturés, et le résultat sera tout à fait acceptable. À l’inverse, utiliser « Low » sur une tâche conséquente dégradera la précision : votre contexte ne sera pas pleinement exploité, et le modèle risque d’inventer des détails ou de prendre des raccourcis qu’il faudra corriger.
Le rapport peut atteindre ×10 entre les tokens de sortie facturés en « Low » et en « High ». Le mode « Medium » offre souvent un bon équilibre.
Je vous conseille cet article de MindStudio, qui vous aide à choisir le bon niveau d’effort et à détecter quand changer de variant.
6 — Des MCPs et skills : oui, quand c’est nécessaire — et pas tous activés en même temps
Vos tokens d’entrée contiennent une partie « system prompt », envoyée à chaque message. Ce system prompt inclut le catalogue de vos MCPs avec leurs descriptions, leurs paramètres attendus… Plus vous avez d’outils activés, plus cette partie fixe sera volumineuse.
Certains MCPs, disposant de nombreuses fonctions, adoptent une stratégie de « discovery » : ils exposent une fonction permettant de découvrir les autres. C’est légèrement plus optimisé, mais une fois les fonctions découvertes, elles s’ajoutent à l’historique de la session et sont donc réenvoyées à chaque appel suivant.
Pour désactiver :
- Sur Opencode :
/mcpspuis espace sur les mcps - Sur Copilot CLI :
/mcp disable <service>
La même logique s’applique aux skills. Les instructions d’une skill sont injectées dans le prompt système dès qu’elle est activée, et consomment des tokens à chaque tour de conversation. Désactivez les skills dont vous n’avez plus besoin (« /skills » puis /new pour démarrer une session propre). Ne gardez actives que celles qui servent la tâche en cours.
L’usage judicieux des MCPs reste bien sûr bénéfique lorsqu’il est justifié : l’agent évitera, par exemple, de récupérer une page entière et de recevoir un dump HTML pour en extraire une information, si un MCP la fournit directement, de manière concise et structurée.
7 — Compression, reprise de session, nouvelle conversation
La compression évite de dépasser le maximum de tokens en entrée en réalisant une synthèse du contexte accumulé. Elle se déclenche souvent automatiquement dans les outils (aux alentours de 80 %) ; à défaut, on tomberait dans un « overcontext » avec des résultats peu précis. On peut la déclencher manuellement avec /compact.
Pour réaliser cette synthèse, un appel à un LLM est nécessaire. Résultat : on paie des tokens d’entrée et de sortie à chaque compression. Sachant qu’on envoie environ 80 % d’un contexte, cela représente un volume non négligeable de tokens. De plus, côté Copilot CLI ou OpenCode, c’est le modèle actuellement utilisé dans la session qui effectue la compression — compresser sous Opus peut faire mal à la facture.
La question à se poser est donc : « Dois-je démarrer une nouvelle session, ou le contexte accumulé jusqu’ici mérite-t-il d’être conservé ? »
Si je prends une session ou je souhaite envoyer une nouvelle fonctionnalité complexe, que je veux envoyer en pull request, je vais surement faire un plan (sous Opus / high), lancer le développement (sous Sonnet / Medium) et arriver à un besoin de compression après 2 ou 3 itérations.
Quelques exemples concrets :
- Plusieurs linters en échec : le contexte précédent ne me sert à rien (la sortie de la commande de lint est suffisamment explicite). Je lance Claude Haiku dans une nouvelle session.
- Plan terminé, tests unitaires oubliés : le contexte est important, je continue la session.
En pratique, au-delà de deux ou trois compressions dans une même session, le confort se dégrade et le coût augmente. Il n’est pas absurde de repartir sur une session propre, en lui fournissant le PLAN.md de la session précédente et en expliquant où vous en êtes.
Sachez également que vous pouvez désactiver la compression automatique sur OpenCode, ou la déclencher plus tôt. Vous éviterez ainsi des compressions non souhaitées lorsque vous n’avez pas l’intention de prolonger la session. (Cette option ne semble pas être disponible sous Copilot CLI.) (doc OpenCode)
{
"$schema": "https://opencode.ai/config.json",
"compaction": {
"auto": false,
"prune": true,
"reserved": 10000
}
}Deux outils utiles pour gérer ses sessions :
/resume: permet de reprendre n’importe quelle session passée là où vous l’avez laissée, y compris tous les checkpoints créés.- Sous-agents (Task) : déléguez l’exploration « sale » (lecture de fichiers, grep, contexte) à un sous-agent. Seule sa synthèse est réinjectée dans votre historique principal, ce qui préserve le contexte de votre session maîtresse.
Pour allez plus loin, la doc copilot sur le context management donne son point de vue sur quand démarrer une nouvelle session, quand réutiliser.
8 — Faites des prompts précis
Moins vous donnez de détails, plus l’IA doit tâtonner avec ses outils, multipliant les requêtes et donc les tokens consommés. Un prompt vague force l’agent à enchaîner des grep, ls ou lectures de fichiers inutiles pour récupérer le contexte qu’il n’a pas.
Quelques réflexes simples :
- Donnez le chemin exact du fichier concerné.
- Spécifiez la ligne de début ou le nom de la fonction.
- Décrivez l’état final attendu pour éviter les allers-retours.
❌ Mauvais : « Fix le bug dans le header »
✅ Bon : « Danssrc/components/Header.tsx, ligne 42, remplace la conditionisLoadingparisPending»
L’impact est double : moins d’appels d’outils = moins de tokens injectés dans l’historique, et une réponse plus directe = moins de tokens de sortie.
9 — Utiliser du texte plutôt que des médias
Sans trop s’étendre : le texte sera toujours plus économique et plus précis qu’une image. Si vous êtes dans la vibe du « Mouth Coding » (coder à la voix), utilisez d’abord un outil de speech-to-text local comme Handy. Pour développer une maquette, préférez un MCP dédié (MCP Figma, par exemple) qu’une image dans le prompt.
Conclusion
Finalement, ces évolutions de tarification devraient peut-être nous amener à réfléchir plus largement à notre usage quotidien de l’IA. Pourquoi faire tourner des data centers à plein régime pour tout et n’importe quoi — et notamment pour des tâches simple qu’on faisait très bien sans IA auparavant ? Les conséquences environnementales, notamment sur la consommation d’eau et l’accaparement des ressources, doivent continuellement nous amener à nous interroger sur le quand et le pourquoi de l’usage de l’IA. Utilisez-la en conscience. Et la meilleure économie de tokens restera toujours le prompt que vous n’enverrez pas.
Sources
- https://www.ionos.fr/digitalguide/sites-internet/developpement-web/les-token-ia/
- https://introl.com/fr/blog/prompt-caching-infrastructure-llm-cost-latency-reduction-guide-2025
- https://www.mindstudio.ai/blog/claude-code-effort-levels-explained
- https://docs.github.com/en/copilot/concepts/agents/copilot-cli/context-management